references/ מול scripts/ (מתי להשתמש במה)
תיקיית סקיל יכולה לכלול שתי תת־תיקיות אופציונליות: references/ ו־scripts/. הן משרתות מטרות שונות והבחירה הלא נכונה ביניהן היא סיבת דחייה תכופה. החוק פשוט: references/ לתוכן סטטי שה־LLM קורא, scripts/ לקוד הרצה שה־LLM מריץ. החלק הקשה הוא לזהות באיזה צד של הקו התוכן שלכם נופל.
references/: קבצים סטטיים שה־LLM קורא לפי דרישה
references/ מחזיק קבצים שה־LLM יכול לקרוא כשהוא צריך אותם: הסברים ב־Markdown, טבלאות lookup ב־JSON, נתוני דוגמה, קבצי template, מפרטי תמונות. ה־LLM קורא אותם דרך כלי קריאת קבצים. הוא לא מריץ אותם.
שימושים טיפוסיים:
- טבלאות lookup: מערך של קידומות אזור ישראליות ממופות לערים, שמור כ־JSON, נקרא כשה־LLM צריך לזהות את מקור מספר טלפון
- תוכן עזר ארוך: הסבר בן 2000 מילים על תהליך מרובה שלבים, שנשאר מחוץ ל־SKILL.md (שצריך להישאר קצר וממוקד ניתוב) ונטען רק כשה־LLM נתקל בשאלה מסוימת
- תבניות: חוזי דוגמה, טפסי דוגמה, נוסח בסיסי שה־LLM מתאים אישית למשתמש
- מפרטי תמונות: הנחיות ליצירת איורים, שמורות בנפרד מהגוף
קובץ טוב ב־references/ הוא משהו שה־LLM צריך רק לפעמים, ולכן טעינה שלו מראש לקונטקסט תבזבז tokens.
scripts/: קוד הרצה שה־LLM יכול להריץ
scripts/ מחזיק קוד שהסוכן יכול להריץ: validators, parsers, חישובים דטרמיניסטיים, קריאות רשת. הסוכן מפעיל סקריפטים דרך כלי ה־shell של הסביבה (Bash ב־Claude Code, המקבילה בסביבות אחרות), קורא stdout/stderr, ומשלב את הפלט המפורסר בתשובה שלו. אין מנגנון "function-call" מובנה לסקריפטים במפרט של Skills. סקריפטים הם executables רגילים שהסוכן מריץ וקורא.
שימושים טיפוסיים:
- חישוב דטרמיניסטי שה־LLM לא צריך לעשות מחדש: אלגוריתם ספרת ביקורת Luhn לתעודות זהות ישראליות (ה־LLM היה גוזר אותו מחדש בצורה לא עקבית אחרת)
- Parsers: פונקציה שלוקחת טקסט גולמי של תלוש משכורת ומחזירה פירוט מובנה ב־JSON
- חיפושים חיצוניים שדורשים API key: פונקציה שקוראת ל־API ממשלתי כדי לחפש פרטי רישום עסק
- קריאות רשת: scraping של טבלה ציבורית, קריאה ל־RSS feed
סקריפטים חייבים להיות עצמאיים (להגדיר את כל התלויות בכותרת הסקריפט), לכלול הערת שימוש ברורה בראש, ולכתוב ל־stdout בפורמט צפוי שה־LLM יכול לנתח.
עץ ההחלטה
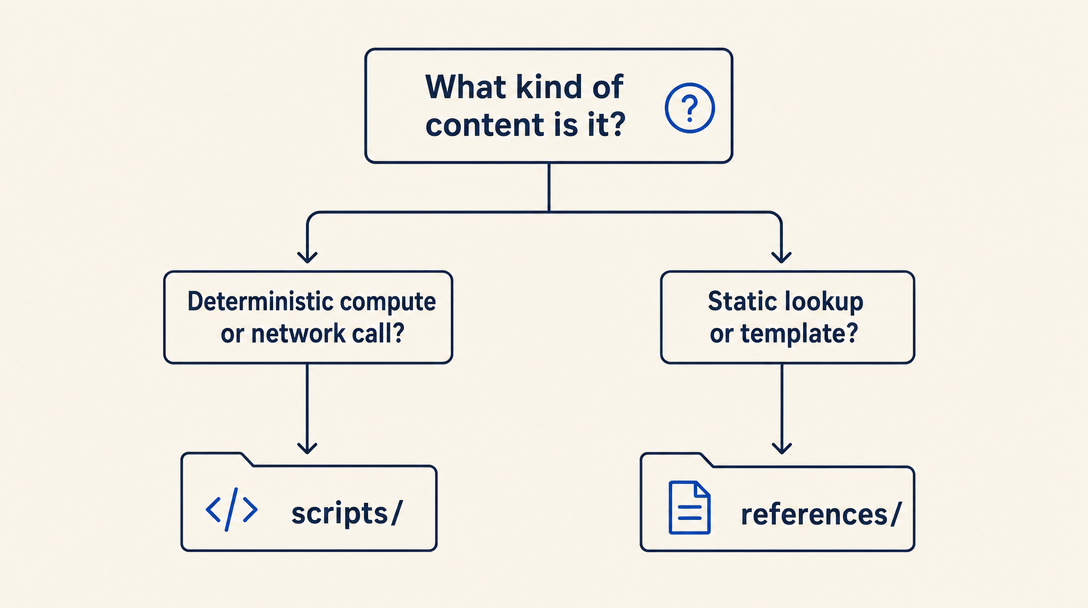
כשיש לכם תוכן שתומך בסקיל, שאלו:
- האם זה חישוב דטרמיניסטי שה־LLM עלול לגזור מחדש שגוי? ←
scripts/ - האם זה דורש API key, קריאת רשת, או כתיבה למערכת קבצים? ←
scripts/ - האם זה lookup סטטי, template, או הסבר ארוך שה־LLM צריך רק לפעמים? ←
references/ - האם זה חוק או דוגמה קצרה ורלוונטית תמיד? ← inline בגוף
SKILL.md - האם זה חוק ארוך ורלוונטי תמיד שה־LLM חייב לדעת תמיד? ← כנראה לא צריך להיות בסקיל. תשקלו system prompt או סקיל אחר שיכסה את זה
גודל קובץ ומבנה
תשמרו על קבצי references/ מתחת ל־5000 מילים כל אחד (~20KB). אם צריך יותר, פצלו לכמה קבצים ותנו ל־LLM לבחור את הנכון. קבצי scripts/ צריכים להיות עצמאיים: סקריפט בודד מתחת ל־~200 שורות קל לתחזוקה. כל דבר גדול יותר כנראה צריך להתפצל או להפוך לחבילה אמיתית.
תימנעו מ:
- הדבקה של טבלת lookup בת 50 שורות לתוך הגוף של SKILL.md. תעבירו את זה ל־
references/<table-name>.jsonותפנו אליו מהגוף ("ראו references/area-codes.json"). - כתיבה של סקריפט Python בתוך הגוף של SKILL.md כקטע קוד. תעבירו את זה ל־
scripts/<name>.pyותפנו אליו. - שמירה של קבצים בינאריים (PNG, ZIP) ב־
references/, אלא אם הם נתוני דוגמה שה־LLM מנתח במפורש.
דוגמאות ללימוד
לדוגמת scripts/ קלאסית, מצאו סקיל שמכיל מימוש קטן של אלגוריתם דטרמיניסטי (Luhn לתעודות זהות ישראליות זו דוגמה טובה). הגוף של SKILL.md מתאר מתי להשתמש באלגוריתם. המתמטיקה עצמה נמצאת בסקריפט. זו הדוגמה הקנונית ל"חישוב דטרמיניסטי שייך ל־scripts/".
לדוגמת references/ מנוגדת, חפשו סקיל ששומר טבלת lookup (קידומות טלפון סלולרי / קווי / שירותים מיוחדים זאת דוגמה נפוצה) כ־JSON ב־references/, במקום להדביק את הטבלה בתוך הגוף.
הטעות הכי נפוצה בפרק 4: הדבקת טבלת lookup ארוכה לתוך הגוף של SKILL.md במקום ל־references/. סימן אזהרה: הגוף הוא 80 אחוז טבלה ו־20 אחוז חוקי החלטה אמיתיים. פתרון: העבירו את הטבלה לקובץ JSON ב־references/ והפנו אליו מהגוף. ניצול ה־tokens משתפר, והגוף חוזר להיות קריא כלוגיקת החלטה.
רוצים להמשיך לקרוא?
התחברו כדי לפתוח את שאר הקורס ולעקוב אחרי ההתקדמות שלכם.